The Hidden Cost of Temperature Excursions—and How to Cut Exceptions Without Slowing Routes

Temperature excursions aren’t “events.” They’re operational debt.
Most ops teams don’t feel the pain of a temperature excursion at the moment it happens.
They feel it later—when diagnosis is delayed, a customer complains, when a specimen needs to be recollected, when a team spends hours arguing over what really happened, and when leadership asks why this keeps repeating.
And by then, the true cost has compounded across three dimensions:
| Time Cost | Service Cost | Reputation Cost |
| Dispatchers rework routes and prioritize re-deliveries Supervisors chase driver statements Ops analysts stitch together logs, emails, and screenshots Customer success spends hours doing damage control | Missed Turnaround-Time (TAT) commitments Delayed Lab diagnosis “Expedite culture” that trains teams to bypass SOPs to keep up | Customers stop trusting the lab capabilities Every future shipment is questioned New bids demand more proof, more audits, and more concessions |
The hard truth: excursions aren’t just thermal failures—they’re workflow failures. And exceptions become expensive when your process can’t answer three simple questions quickly:
- Did an excursion actually occur (or is it a false alarm)?
- Where did it happen—handoff, dwell, linehaul, delivery, or storage?
- What needs to change so it doesn’t repeat?
Why exception volumes grow even when you “add more monitoring.”
A common pattern: teams deploy sensors and alerts… and exception volume increases. Not because performance got worse, but because:
- Medical courier totes are not validated for operating conditions
- Alerts aren’t mapped to real operational thresholds
- Notifications aren’t actionable
- Data is trapped across devices, vendors, platforms, and spreadsheets
- “Investigation mode” becomes manual and slow
- Corrective actions aren’t standardized across assets, routes, and drivers
So you end up with exception noise, and operators start ignoring alerts—until a major customer escalation forces attention.
To fix this, you don’t need more monitoring.
You need an Exception Management System—a playbook that turns every alert into a fast, consistent decision.
The Exceptions Playbook: Cut Exceptions Without Slowing Routes
This playbook is designed for courier and logistics operators moving temperature-sensitive healthcare shipments—where every additional step creates friction.
Step 1: Classify exceptions into 3 levels (so every alert doesn’t become a fire drill)
Most operations treat all alerts equally. That’s how you get chaos.
Instead, define three operational categories:
Level 1: “Informational”
- Small deviations within a safe buffer
- Short-duration spikes (e.g., door open moment)
- No exposure risk based on profile/hold time
- Read it & skip. Be Informed.
Action: Auto-log and monitor (no human escalation)
Level 2: “Actionable”
- Risk is possible, but not confirmed
- Duration or severity needs review
- May require prevention action (reroute, reduce dwell, verify pack-out)
- Review it. Need attention if it repeats.
Action: Ops review within shift
Level 3: “Critical”
- Confirmed out-of-spec exposure
- Known lane vulnerability or repeated incident
- Customer visibility is required
- Resolve it. Need Actions to be taken.
Action: Escalate, generate a proof packet, and trigger CAPA (Corrective and Preventive Action)
Outcome: You stop treating 100 alerts like 100 emergencies. You engage people only where human judgment is needed.
Step 2: Move from “temperature alerts” to “workflow alerts”
A temperature chart alone rarely tells the story.
What matters operationally is where the excursion occurred in the workflow. Standardize exception tagging by the stage where it most likely happened:
- Collection / pickup
- Handoff / custody transfer
- Vehicle dwell / missed scan
- Linehaul / cross-dock
- Delivery delay / failed attempt
- Storage at facility / staging zone
Action: Every exception must map to a workflow stage in the first 15 minutes.
Outcome: Root Cause Analysis becomes faster because teams investigate the right part of the chain, not the entire journey.
Step 3: Set “investigation windows” so RCA (Root Cause Analysis) doesn’t drag for days
Exception investigations die when they stay open too long.
Set timeboxed standards:
- 15 minutes: classify (L1/L2/L3) with tag workflow stage
- 2 hours: confirm facts (timestamp, location, duration) and assign owner
- 24–48 hours: close RCA with a preventive action (not just a report)
Action: Treat exceptions like tickets with SLAs (Service Level Agreements), not open-ended debates.
Outcome: Faster closure, fewer repeat incidents, less time spent “finding the story.”
Step 4: Replace manual reconstruction with a “Proof Packet”
Your customers don’t want a narrative. They want proof.
A Proof Packet is a standardized, exportable bundle that answers:
- Where the shipment was (at any time and location)
- What the temperature exposure looked like (with thresholds)
- Whether the pack-out was correct
- Whether an SOP deviation occurred
- What corrective action was taken
Action: Standardize this packet so it’s generated the same way every time.
Outcome: Escalations become shorter, trust increases, and renewals get easier.
Step 5: Fix the top 20% of lanes causing 80% of exceptions
Most teams try to “improve everywhere.” That slows routes.
Instead, isolate exception hotspots:
- Lanes with high dwell variability
- Facilities with inconsistent staging practices
- Drivers with repeated custody/scan gaps
- Time windows where heat/cold exposure spikes
Action: Prioritize lane risk reduction, not universal changes.
Outcome: Exception reduction without adding steps to every route.
The goal isn’t zero excursions. It’s zero chaos.
Even best-run operations will face weather swings, traffic spikes, missed handoffs, and facility delays.
The difference is whether an excursion becomes:
- a minor ticket closed in hours, or
- a multi-day escalation with customer fallout
This is what modern exception management is really about: faster clarity, fewer repeats, and less friction.
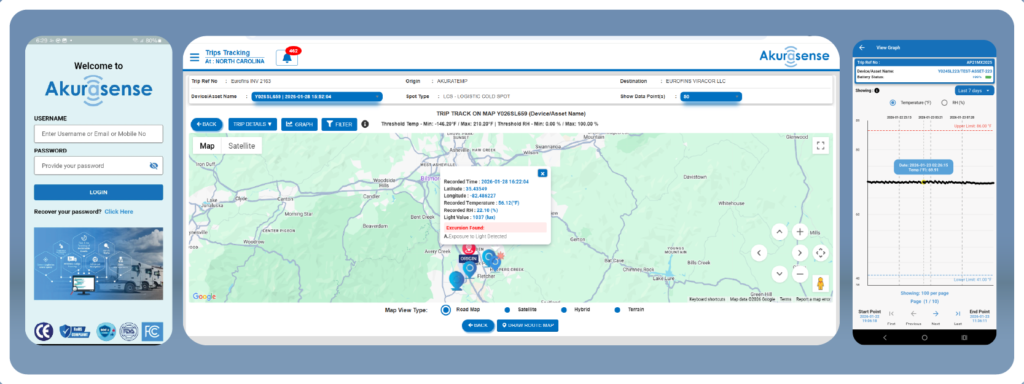
Where Akuratemp fits: reduce noise, speed RCA, standardize prevention
Akuratemp® supports exception reduction in two complementary ways:
1) Akurasense™ monitoring and alerting that’s built for operations
Instead of turning every data point into noise, the Akurasesne™ platform helps you:
- Verify the readiness of the courier tote before trip initiation
- Maintain the courier tote chain-of-custody along the route
- Capture time, temperature, and location at each lockbox pickup
- Monitor the courier tote temperature in real-time along the route
- Trigger alerts that match your real thresholds and workflows
- Maintain audit-ready logs and reporting for customers
- Provides asset, in-transit & storage analytics for continuous improvement initiatives
2) Optymize® workflow standardization
Most exceptions repeat because SOPs vary across:
- Asset validation & handling
- Courier routes
- Courier discipline
- Collection sites
- Asset handoffs
Optymize® helps map current-state workflow for assets, couriers, and courier routes, identify risks and process waste, and implement validated assets with standardized processes to maximize conformance
The combined result: fewer exceptions, faster investigations, and fewer escalations—without slowing daily routes.
A practical next step: run a 14-day Exceptions Health Check
If you operate cold-chain routes, here’s a simple way to start without disruption:
Over 14 days run a pilot study by:
- Identifying the top 5 courier routes by exception volume
- Digitize assets on this route to capture time & location-stamped temperature data
- Analyze all asset data per courier route
- Analyze all asset data per asset type
- Develop corrective actions
Then apply the playbook to one route first. Improve there, then scale.
Schedule a conversation with Akuratemp, and together we’ll map your operations, close the gaps you can’t see today, and build a cold chain your customers can stand behind.

