Sensor-Agnostic and Asset-First Visibility for Medical Specimen Transport

There’s a familiar moment in every lab courier operation and every multi-site lab network. It usually doesn’t start with a “critical incident.” It starts with a simple question that lands in the middle of a busy day:
“Can you prove this shipment remained controlled?”
And then the room changes.
Not because the team doesn’t care. Not because they don’t know what “good” looks like… but because the truth is hard to assemble when evidence is scattered— across different assets specimens came in and out of, across different sensors deployed in the assets, different portals where sensor data is tracked, different handoff practices between couriers along the specimen transport journey, and different people’s memories.
When the specimen fails to test and the specimen integrity during transport is questioned, what follows is the hidden workflow of cold chain: the rework, the escalation calls, the screenshot-chasing, the “who had it last” conversations. This is the operational cost most teams don’t budget for—until it becomes their weekly normal.
That’s the real reason we built Akurasense.
Not because the world needed one more temperature dashboard. But because lab courier and specimen transport needed a platform that could follow the specimen journey from collection to laboratory showing temperature & location visibility of each asset that it came in and out of with traceability of who had the custody of the asset – scaling proof and performance without scaling overhead.
Definition: What “specimen transport” actually includes
Specimen transport is the set of steps that move a clinical specimen from collection to laboratory while preserving integrity. It includes not only the “drive,” but also staging, handoffs, storage, and receiving checks—each of which can introduce risk.
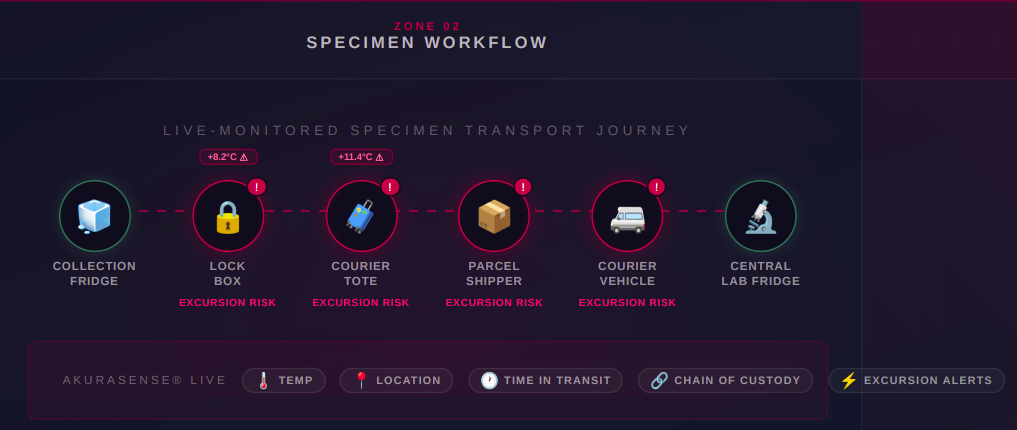
The failures that hurt labs most rarely happen in the middle of the route. They happen at the edges: staging in the lockbox, a handoff between couriers without clear custody, a tote sitting an extra hour because a pickup window slipped, a refrigerated vehicle idling with frequent door cycles, a fixed refrigerator drifting overnight.
And if you’re honest, you’ve probably seen this: the longer it takes to establish what happened, the more expensive the incident becomes—regardless of whether it ends in a rejection.
The uncomfortable truth: We don’t have a data problem. We have an intelligence problem.
The industry has plenty of sensors. Plenty of “monitoring.” Plenty of temperature graphs.
But the cold chain breaks at scale because monitoring alone does not create operational intelligence.
When teams say, “We need better visibility,” they often mean, “we need the right information in time to plan a response.” That’s not the same thing as collecting more readings. It’s about minimizing risk of specimen rejection and making the workflow efficient .
An intelligent operation can answer these questions quickly, without heroics:
- Which asset within the journey showed non conformance?
- Where was the asset, and for how long?
- Who had custody at the moments that matter?
- How long was the asset out of temperature range?
- Who received excursion notifications and an audit trail of what happened next?
If those answers take hours—or require someone to pull data from three portals—you don’t have a visibility layer. You have a reconstruction problem.
That is what Akurasense is designed to eliminate.
Definition: Sensor-agnostic platform
A sensor-agnostic platform is a monitoring and evidence system that can integrate data from multiple sensor types and manufacturers instead of locking you into one hardware ecosystem.
In lab courier and specimen transport, sensor-agnostic isn’t a nice-to-have. It’s reality. Most operations are a patchwork:
- legacy devices at one site
- a different sensor vendor at another
- refrigerated vehicles with their own telemetry
- fixed storage monitored by facilities systems
- packaging assets (totes, shippers) with embedded or paired sensors
- partners who won’t change hardware just because you prefer it
If you try to “standardize” the network by forcing one sensor everywhere, you don’t get better operations. You get change-management friction, partial adoption, and new data silos.
So we took a different approach: standardize the operating model first, and let sensors feed the model—without dictating the brand of every device.
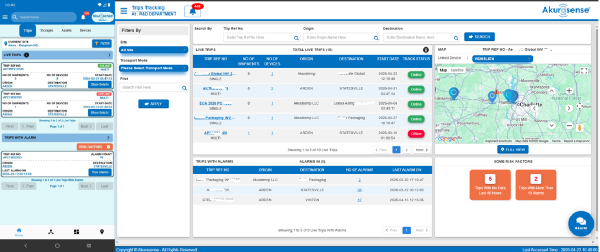
Akurasense is not specimen tracking. It is not courier route optimization.
I want to be blunt about this because it’s where many platforms get misunderstood.
Specimen tracking typically means tracking a specimen identifier through steps (often connected to LIS workflows).
Route optimization means improving driver routes and schedules to reduce miles or time.
Akurasense is neither.
Akurasense is a specimen cold chain operational intelligence platform that creates end to end traceability of asset performance, a non-conformance audit trail and a chain of asset custody for the equipment that touches specimens—transport and storage assets. That includes the physical objects that actually create or prevent risk: lockboxes, totes, shippers, refrigerated vehicles, and fixed cold storage.
The difference is more than semantics.
When a customer asks for proof, they’re not asking for a route map. They’re asking:
“Can you show that the operation remained controlled?”
That proof lives in how assets were used, where they were staged, who had custody, and how they performed during the real-world messiness of daily operations.
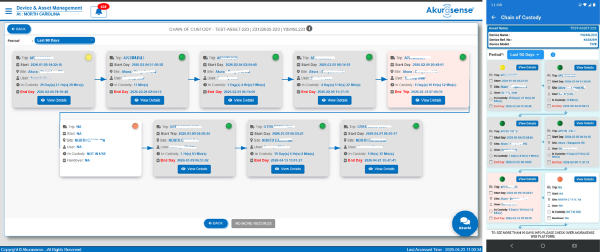
Definition: Chain of custody
Chain of custody is the recorded sequence of custody transfers and handling events that shows who had responsibility for an item at each point in time.
In cold chain, the chain-of-custody isn’t just a compliance artifact. It is an operations KPI—because custody gaps are where escalations start.
When custody is unclear, every incident turns into debate:
- “It was fine when we handed it off.”
- “It wasn’t fine when we received it.”
- “We don’t know where it sat.”
- “We don’t know who had it.”
Debate costs time. Time costs money. And over time, debate costs trust.
So we designed Akurasense to make custody and performance visible across the workflow in a way operations can use it intelligently—not just in a way compliance can archive. This feature not only enables the traceability of who has custody but also triggers the change in who gets notified when there is an excursion.
The shift that matters: from shipment-centric thinking to asset-based workflows
If there’s one opinion I’ll stand behind, it’s this:
Cold chain reliability improves faster when you manage it as an asset operating system, not a series of shipments.
A shipment is temporary. An asset workflow repeats.
And the cold chain doesn’t fail because “shipment #3821” was unlucky. It fails because the same workflow breaks in the same ways until you design an improvement.
That’s why Akurasense treats different asset types uniquely—not as generic “temperature events.”
Definition: Asset-based workflow
An asset-based workflow is an operational model where each asset type has its own states, guardrails, evidence expectations, place in workflow and exception rules because it behaves differently in real life.
A lockbox is not a courier tote.
A courier tote is not a parcel shipper.
A parcel shipper is not a refrigerated vehicle.
A refrigerated vehicle is not a fixed refrigerator/freezer.
They all carry temperature risk, but the risk profile isn’t the same and they are handled differently in the specimen transport workflow
So in Akurasense, these are distinct workflows:
Lockbox workflow: custody transitions and dwell time are often the risk; the key question is whether the lockbox was conditioned before the specimens were placed, did the pickup happen at the scheduled time, if the lockbox was still within its temp range when the pickup happened, and did the designated courier do the pickup.
Medical courier tote workflow: the “multi-stop reality” matters—door cycles, repeated opens, and dwell between stops. The performance question is “when there was an excursion, was a notification initiated, was the response in time, and do we have enough data to improve next time around.”
Home care courier tote workflow: variability is the environment—unpredictable handoff timing, uncontrolled staging at residences or home care sites, and higher dependence on clear custody capture.
Parcel shipper workflow: long duration and handoffs dominate—conditioning discipline, transfer events, and proof of packet readiness become central.
Refrigerated vehicle workflow: the asset is a moving cold room—door openings, ambient exposure, and route patterns matter more than a single linehaul segment.
Fixed storage workflow: continuity is everything—overnight drift, weekend alarms, maintenance governance, and calibration discipline are what determine reliability.
This is how you stop applying one blunt monitoring approach to every reality.
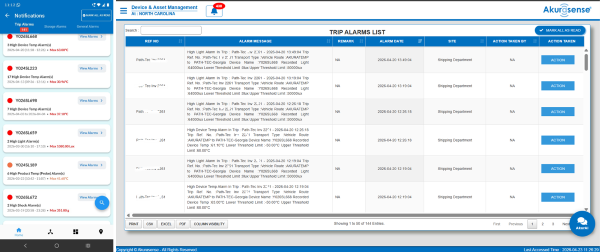
What “visibility” should do in a cold chain operation
In most operations, “visibility” has been reduced to “I can see a temperature graph.”
But graphs don’t run your business. Decisions do.
Operational visibility should do three things:
- Reduce unknowns during exceptions (so you don’t waste hours reconstructing).
- Standardize response (so closure doesn’t depend on who is on shift).
- Create learning loops (so the same problems don’t repeat).
That third point is where most platforms stop short. They log, they alert, they archive.
But logging isn’t improvement.
Definition: Asset performance analytics
Asset performance analytics is the use of operational data from assets (temperature behavior, dwell patterns, custody events, exception closures) to measure reliability and identify repeat failure modes.
This is where Akurasense becomes a platform for operational intelligence which is more than a monitoring system.
Once you treat assets as repeatable workflows, you can answer questions that directly impact cost and outcomes:
Which asset types generate the most exceptions?
Which routes have repeat dwell issues at the same stop?
Which sites consistently break staging rules?
Where does “in transit” get blamed when the real drift happens during staging?
Which corrective actions actually reduced repeats?
This is the foundation of continuous improvement.
Definition: Continuous improvement in cold chain
Continuous improvement (CI) is a disciplined approach to reducing repeat problems by measuring performance, identifying root causes, standardizing fixes, and verifying effectiveness over time.
CI only works when evidence is consistent and comparable.
If every exception is documented differently, and every site uses different “proof,” you can’t learn. You can only react.
Akurasense was built to make CI practical in cold chain operations by turning exceptions into structured signals—so teams can move from incident response to system improvement.
Why we say “proof is the value, performance is the differentiator”
In healthcare logistics, trust is earned when you can provide documented insights without drama.
Proof reduces disputes. Proof reduces escalations. Proof reduces rework.
But performance analytics reduces the future cost entirely—because it helps you stop repeats.
That’s how leaders win. Not by fighting yesterday’s incident faster, but by making tomorrow’s incident less likely.
The thought I’ll leave you with…
For years, cold chain has been treated like a packaging problem, or a sensor problem.
Packaging matters. Sensors matter.
But at scale, the biggest risk is the workflow—and workflows live in assets and custody.
That’s why Akurasense exists:
A sensor-agnostic platform, designed around asset-based workflows, built to create defensible proof and measurable performance—without increasing operational overhead.
Not specimen tracking. Not route optimization.
An intelligent operating system for the assets that move and store specimens.
If you want to see what this looks like in your operation
If you’re dealing with recurring exceptions, fragmented monitoring, or inconsistent evidence across sites, Request an Audit.
We’ll map your specimen workflows across assets (fridge – lockbox → tote → shipper → vehicle → fridge), understand what “good” means for each asset, measure performance of each asset and compare to the benchmark, identify custody and performance visibility breaks, and share a practical plan to improve, validate and standardize operational practices —while setting you up for continuous improvement.
Because the goal isn’t more monitoring. The goal is intelligent operations at scale.


